> For the complete documentation index, see [llms.txt](https://labspc.gitbook.io/cnippets/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://labspc.gitbook.io/cnippets/chap6.-jie-gou-yu-lian-he/6.1-jie-gou-structures.md).
# 6.1 结构 Structures
### 6.1.1 结构的概念
 在 Chap5 讲过数组,结构也是一种重要的数据结构。结构 Structures 可以理解为一个盒子,内装不同类型的数据,而后用一个标签 Tag 来进行打包,它是用户自定义的。
### 6.1.2 结构(结构体)变量的声明
结构体的定义形式如下:
```
struct Person {
char name[50];
int age;
double height;
};
```
在上面的示例中,我们定义了一个名为 `Person` 的结构体,它包含了三个成员:`name`(字符数组)、`age`(整数)、`height`(双精度浮点数)。结构体允许您组织和存储不同类型的数据,并且可以根据需要创建多个结构体变量。
注意:**右花括号后的分号必不可少,它表示生命的结束。**另外,**结构的成员在内存中是按照声明的顺序存储的,**这一点在声明结构时很有用。
### 6.1.3 结构和内建(build-in)数据类型有什么区别
C 语言中有两种主要的数据类型:基本数据类型(Primitive Data Types,内建的)和结构体(Structures)。
基本数据类型是编程语言中预定义的基本数据单元。在 C 语言中,常见的基本数据类型包括:
1. int: 用于表示整数。
2. char: 用于表示单个字符。
3. double: 用于表示双精度浮点数。
4. float: 用于表示单精度浮点数。
这些基本数据类型具有以下特点:
* int: 通常占据 4 个字节,可以存储整数值,包括正数和负数。
* char: 通常占据 1 个字节,用于表示字符,例如字母、数字或特殊字符。
* double: 通常占据 8 个字节,提供更高的精度,适用于存储大范围的浮点数。
* float: 通常占据 4 个字节,提供单精度浮点数,适用于存储小范围的浮点数。
结构体是一种用户自定义的数据类型,它允许将不同类型的数据组合在一起以创建新的数据类型。结构体通常用于表示具有多个相关属性的对象。
区别总结如下:
* 基本数据类型是编程语言内置的,而结构体是用户自定义的。
* 基本数据类型用于存储单个值,而结构体用于存储多个相关属性。
* 基本数据类型具有固定的大小和内存布局,而结构体的大小取决于其成员的大小和排列。
* 基本数据类型具有不同的取值范围和精度,而结构体的成员可以是任何数据类型。
基本数据类型用于存储单一的数值,而结构体用于表示更复杂的数据结构,例如人员信息、图形对象等。根据您的需求选择合适的数据类型。
### 6.1.5 结构变量的初始化和成员操作
这个例子用到了字符指针,后文在学习字符串的时候会再次提到。
```
#include
// 定义结构
struct Person
{ char *name;
//char name[50];
int age;
float salary;
};
int main()
{
// 声明一个结构类型的变量
struct Person person1;
// 使用点操作符(.)访问结构中的成员,并为其赋值
//person1.name = malloc(50 * sizeof(char));
//strcpy(person1.name, "John");
person1.name = "John";
person1.age = 30;
person1.salary = 2500.50;
// 打印结构成员的值
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Salary: %.2f\n", person1.salary);
return 0;
}
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 解释: │
│ 如果采用下列写法,用到了一个指向静态字符串的指针,person1.name被定义为指向字符的指针 │
│ 从而,跳过字符串拷贝,不使用strcpy()函数 │
│ char *name; │
│ //char name[50]; │
│ 输出: │
│ Name: John │
│ Age: 30 │
│ Salary: 2500.50 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
```
SOL2 的方法,可以多次调试尝试,有关尝试部分已经写好并注释。其中,在未申请内存的情况下,程序仍然可以编译运行,这背后的逻辑我暂时还不懂。
```
#include
#include
#include
// 定义结构
struct Person
{ //char *name;
char name[50];
int age;
float salary;
};
int main()
{
// 声明一个结构类型的变量
struct Person person1;
// 使用点操作符(.)访问结构中的成员,并为其赋值
//person1.name = malloc(50 * sizeof(char));
//char *name = malloc(50 * sizeof(char));
char *name = "John";
strcpy(person1.name, "John");
//person1.name = "John";
person1.age = 30;
person1.salary = 2500.50;
// 打印结构成员的值
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Salary: %.2f\n", person1.salary);
return 0;
}
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 解释: │
│ 如果 person1.name 是一个字符数组(例如 char name[50]),那么您不能将 malloc 返回的地址赋值给它。 │
│ char *name; │
│ //char name[50]; 数组类型是不能被赋值的。
| 强行调试会产生一个 error: array type 'char[50]' is not assignable
| 由此,还可以不改变char[50]数组,而直接使用char *name进行 malloc
| 最后,这一版的debug,并没有分配内存,程序还是成功编译,不得其解 │
│ 输出: │
│ Name: John │
│ Age: 30 │
│ Salary: 2500.50 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
```
### 6.1.4 结构的大小与内存对齐(如何存储)
结构体的大小是由其**成员的大小和排列方式决定的**。在 C 语言中,结构体的大小通常等于其所有成员大小的总和,但由于**内存对齐(Memory Alignment)**的原因,实际大小可能会大于成员大小的总和。
让我们来计算一下上面示例中的 `struct Person` 结构体的大小:
```
struct Person {
char name[50]; // 50 bytes
int age; // 4 bytes
double height; // 8 bytes
};
```
* `char name[50]` 占据 50 字节。
* `int age` 占据 4 字节。
* `double height` 占据 8 字节。
结构体的总大小为 50 + 4 + 8 = 62 字节。
然而,由于内存对齐的原因,编译器通常会将结构体的大小舍入到一个特定的边界(通常是成员中最大数据类型的大小)以提高访问速度。在大多数系统上,`double` 是最大的基本数据类型,大小为 8 字节。因此,结构体的大小将被舍入到 8 的倍数。
因此,对于 `struct Person` 结构体,在大多数系统上,其大小将是 64 字节(舍入到 8 字节的倍数)。这意味着,在内存中,每个 `struct Person` 实例将占据 64 字节的空间。
具体的大小和内存布局可能因编译器和目标系统而异,但通常会遵循内存对齐的规则。**这也是为什么结构体大小可能会比成员大小的总和要大的原因。**
内存对齐(Memory Alignment)是一种处理计算机内存中数据存储位置的规则,其主要目的是提高访问内存的效率。内存对齐规则在不同的计算机体系结构和编程语言中略有不同,但通常包括以下几个重要方面:
1. 数据类型的对齐要求:每种数据类型(例如,`int`、`double`、`char`等)在内存中有其自己的对齐要求。对齐要求表示数据在内存中存储时必须**从内存地址的某个特定偏移位置开始,而不是任意位置**。例如,`int` 通常要求在内存中从偶数地址开始,`double` 可能要求从地址是 4 或 8 的倍数的位置开始。
2. 最大对齐要求:内存对齐要求是由数据类型中对齐要求中最大的那个决定的。这是为了确保每个数据类型都满足其对齐要求。例如,如果一个结构体包含 `int` 和 `double`,则其对齐要求将等于 `double` 的对齐要求,因为 `double` 的对齐要求通常是最大的。
3. 填充字节:为了满足对齐要求,编译器可能会在结构体的成员之间插入额外的字节,这些字节通常被称为“填充字节”或“填充位”。填充字节确保结构体的每个成员都从正确的内存地址开始。
4. 数据访问性能:内存对齐的主要目标是提高数据访问的性能。当数据按照对齐要求存储在内存中时,CPU 可以更有效地访问这些数据,而不需要额外的复杂计算。这对于大规模数据处理和多线程编程非常重要。
下面是一个示例,说明内存对齐的概念:
假设在一个系统上,`int` 的对齐要求是 4 字节,`double` 的对齐要求是 8 字节。现在考虑以下结构体:
```
struct Example {
char a; // 1 字节
int b; // 4 字节
double c; // 8 字节
};
```
* `char a` 只占用 1 字节,没有对齐要求。
* `int b` 需要 4 字节,必须从地址是 4 的倍数的位置开始,因此可能需要 3 字节的填充。
* `double c` 需要 8 字节,必须从地址是 8 的倍数的位置开始,因此可能需要 3 字节的填充。
因此,`struct Example` 的总大小可能是 16 字节(1 字节 + 3 字节填充 + 4 字节 + 8 字节),即使成员的大小之和只有 13 字节。
内存对齐规则确保了数据存储的有效性和性能,但也可能导致内存的一些浪费。因此,在设计数据结构时需要考虑内存对齐的影响。
**为什么需要内存对齐?**
在 Chap5 讲过数组,结构也是一种重要的数据结构。结构 Structures 可以理解为一个盒子,内装不同类型的数据,而后用一个标签 Tag 来进行打包,它是用户自定义的。
### 6.1.2 结构(结构体)变量的声明
结构体的定义形式如下:
```
struct Person {
char name[50];
int age;
double height;
};
```
在上面的示例中,我们定义了一个名为 `Person` 的结构体,它包含了三个成员:`name`(字符数组)、`age`(整数)、`height`(双精度浮点数)。结构体允许您组织和存储不同类型的数据,并且可以根据需要创建多个结构体变量。
注意:**右花括号后的分号必不可少,它表示生命的结束。**另外,**结构的成员在内存中是按照声明的顺序存储的,**这一点在声明结构时很有用。
### 6.1.3 结构和内建(build-in)数据类型有什么区别
C 语言中有两种主要的数据类型:基本数据类型(Primitive Data Types,内建的)和结构体(Structures)。
基本数据类型是编程语言中预定义的基本数据单元。在 C 语言中,常见的基本数据类型包括:
1. int: 用于表示整数。
2. char: 用于表示单个字符。
3. double: 用于表示双精度浮点数。
4. float: 用于表示单精度浮点数。
这些基本数据类型具有以下特点:
* int: 通常占据 4 个字节,可以存储整数值,包括正数和负数。
* char: 通常占据 1 个字节,用于表示字符,例如字母、数字或特殊字符。
* double: 通常占据 8 个字节,提供更高的精度,适用于存储大范围的浮点数。
* float: 通常占据 4 个字节,提供单精度浮点数,适用于存储小范围的浮点数。
结构体是一种用户自定义的数据类型,它允许将不同类型的数据组合在一起以创建新的数据类型。结构体通常用于表示具有多个相关属性的对象。
区别总结如下:
* 基本数据类型是编程语言内置的,而结构体是用户自定义的。
* 基本数据类型用于存储单个值,而结构体用于存储多个相关属性。
* 基本数据类型具有固定的大小和内存布局,而结构体的大小取决于其成员的大小和排列。
* 基本数据类型具有不同的取值范围和精度,而结构体的成员可以是任何数据类型。
基本数据类型用于存储单一的数值,而结构体用于表示更复杂的数据结构,例如人员信息、图形对象等。根据您的需求选择合适的数据类型。
### 6.1.5 结构变量的初始化和成员操作
这个例子用到了字符指针,后文在学习字符串的时候会再次提到。
```
#include
// 定义结构
struct Person
{ char *name;
//char name[50];
int age;
float salary;
};
int main()
{
// 声明一个结构类型的变量
struct Person person1;
// 使用点操作符(.)访问结构中的成员,并为其赋值
//person1.name = malloc(50 * sizeof(char));
//strcpy(person1.name, "John");
person1.name = "John";
person1.age = 30;
person1.salary = 2500.50;
// 打印结构成员的值
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Salary: %.2f\n", person1.salary);
return 0;
}
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 解释: │
│ 如果采用下列写法,用到了一个指向静态字符串的指针,person1.name被定义为指向字符的指针 │
│ 从而,跳过字符串拷贝,不使用strcpy()函数 │
│ char *name; │
│ //char name[50]; │
│ 输出: │
│ Name: John │
│ Age: 30 │
│ Salary: 2500.50 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
```
SOL2 的方法,可以多次调试尝试,有关尝试部分已经写好并注释。其中,在未申请内存的情况下,程序仍然可以编译运行,这背后的逻辑我暂时还不懂。
```
#include
#include
#include
// 定义结构
struct Person
{ //char *name;
char name[50];
int age;
float salary;
};
int main()
{
// 声明一个结构类型的变量
struct Person person1;
// 使用点操作符(.)访问结构中的成员,并为其赋值
//person1.name = malloc(50 * sizeof(char));
//char *name = malloc(50 * sizeof(char));
char *name = "John";
strcpy(person1.name, "John");
//person1.name = "John";
person1.age = 30;
person1.salary = 2500.50;
// 打印结构成员的值
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Salary: %.2f\n", person1.salary);
return 0;
}
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 解释: │
│ 如果 person1.name 是一个字符数组(例如 char name[50]),那么您不能将 malloc 返回的地址赋值给它。 │
│ char *name; │
│ //char name[50]; 数组类型是不能被赋值的。
| 强行调试会产生一个 error: array type 'char[50]' is not assignable
| 由此,还可以不改变char[50]数组,而直接使用char *name进行 malloc
| 最后,这一版的debug,并没有分配内存,程序还是成功编译,不得其解 │
│ 输出: │
│ Name: John │
│ Age: 30 │
│ Salary: 2500.50 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
```
### 6.1.4 结构的大小与内存对齐(如何存储)
结构体的大小是由其**成员的大小和排列方式决定的**。在 C 语言中,结构体的大小通常等于其所有成员大小的总和,但由于**内存对齐(Memory Alignment)**的原因,实际大小可能会大于成员大小的总和。
让我们来计算一下上面示例中的 `struct Person` 结构体的大小:
```
struct Person {
char name[50]; // 50 bytes
int age; // 4 bytes
double height; // 8 bytes
};
```
* `char name[50]` 占据 50 字节。
* `int age` 占据 4 字节。
* `double height` 占据 8 字节。
结构体的总大小为 50 + 4 + 8 = 62 字节。
然而,由于内存对齐的原因,编译器通常会将结构体的大小舍入到一个特定的边界(通常是成员中最大数据类型的大小)以提高访问速度。在大多数系统上,`double` 是最大的基本数据类型,大小为 8 字节。因此,结构体的大小将被舍入到 8 的倍数。
因此,对于 `struct Person` 结构体,在大多数系统上,其大小将是 64 字节(舍入到 8 字节的倍数)。这意味着,在内存中,每个 `struct Person` 实例将占据 64 字节的空间。
具体的大小和内存布局可能因编译器和目标系统而异,但通常会遵循内存对齐的规则。**这也是为什么结构体大小可能会比成员大小的总和要大的原因。**
内存对齐(Memory Alignment)是一种处理计算机内存中数据存储位置的规则,其主要目的是提高访问内存的效率。内存对齐规则在不同的计算机体系结构和编程语言中略有不同,但通常包括以下几个重要方面:
1. 数据类型的对齐要求:每种数据类型(例如,`int`、`double`、`char`等)在内存中有其自己的对齐要求。对齐要求表示数据在内存中存储时必须**从内存地址的某个特定偏移位置开始,而不是任意位置**。例如,`int` 通常要求在内存中从偶数地址开始,`double` 可能要求从地址是 4 或 8 的倍数的位置开始。
2. 最大对齐要求:内存对齐要求是由数据类型中对齐要求中最大的那个决定的。这是为了确保每个数据类型都满足其对齐要求。例如,如果一个结构体包含 `int` 和 `double`,则其对齐要求将等于 `double` 的对齐要求,因为 `double` 的对齐要求通常是最大的。
3. 填充字节:为了满足对齐要求,编译器可能会在结构体的成员之间插入额外的字节,这些字节通常被称为“填充字节”或“填充位”。填充字节确保结构体的每个成员都从正确的内存地址开始。
4. 数据访问性能:内存对齐的主要目标是提高数据访问的性能。当数据按照对齐要求存储在内存中时,CPU 可以更有效地访问这些数据,而不需要额外的复杂计算。这对于大规模数据处理和多线程编程非常重要。
下面是一个示例,说明内存对齐的概念:
假设在一个系统上,`int` 的对齐要求是 4 字节,`double` 的对齐要求是 8 字节。现在考虑以下结构体:
```
struct Example {
char a; // 1 字节
int b; // 4 字节
double c; // 8 字节
};
```
* `char a` 只占用 1 字节,没有对齐要求。
* `int b` 需要 4 字节,必须从地址是 4 的倍数的位置开始,因此可能需要 3 字节的填充。
* `double c` 需要 8 字节,必须从地址是 8 的倍数的位置开始,因此可能需要 3 字节的填充。
因此,`struct Example` 的总大小可能是 16 字节(1 字节 + 3 字节填充 + 4 字节 + 8 字节),即使成员的大小之和只有 13 字节。
内存对齐规则确保了数据存储的有效性和性能,但也可能导致内存的一些浪费。因此,在设计数据结构时需要考虑内存对齐的影响。
**为什么需要内存对齐?**
 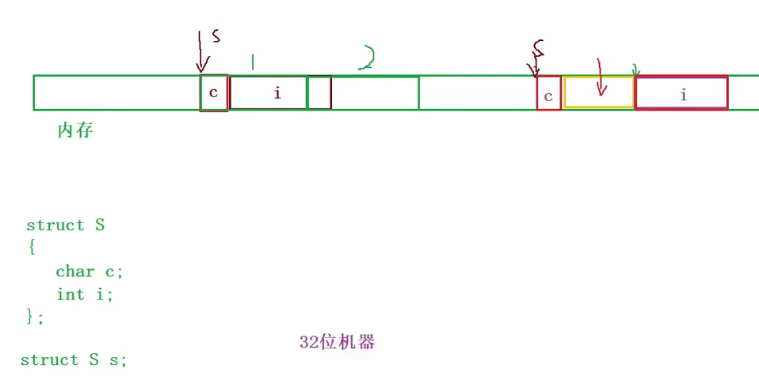先解释第一点,拿空间换时间。在上述这个例子中:左半部分是未进行内存对齐的样子,在读取`i`的时候,一次读取不完,要读取两次。 右半部分是内存对齐之后的样子,读取`i` 一次就读取完整,但存在一个问题,这样做会浪费3个字节的内存。
再解释第二点,既要满足对齐规则,由要节省空间。在 6.1.2 中提到,“另外,**结构的成员在内存中是按照声明的顺序存储的,**这一点在声明结构时很有用。”。
### 6.1.5 偏移量计算与 offsetof 函数
**结构体内存对齐中的偏移量(offset)是指结构体成员相对于结构体起始地址的位移量**。
具体来说:
* 每个结构体成员都有一个偏移量,表示该成员相对于结构体起始地址的距离。
* 第一个成员的偏移量总是0,因为它就是从结构体的起始地址开始的。
* 后续成员的偏移量则与前一个成员的偏移量和大小有关。编译器会根据对齐规则计算出每个成员的偏移量。
* 偏移量为0的意思就是这个成员在结构体的最开始位置,没有间隔。
举个例子:
先解释第一点,拿空间换时间。在上述这个例子中:左半部分是未进行内存对齐的样子,在读取`i`的时候,一次读取不完,要读取两次。 右半部分是内存对齐之后的样子,读取`i` 一次就读取完整,但存在一个问题,这样做会浪费3个字节的内存。
再解释第二点,既要满足对齐规则,由要节省空间。在 6.1.2 中提到,“另外,**结构的成员在内存中是按照声明的顺序存储的,**这一点在声明结构时很有用。”。
### 6.1.5 偏移量计算与 offsetof 函数
**结构体内存对齐中的偏移量(offset)是指结构体成员相对于结构体起始地址的位移量**。
具体来说:
* 每个结构体成员都有一个偏移量,表示该成员相对于结构体起始地址的距离。
* 第一个成员的偏移量总是0,因为它就是从结构体的起始地址开始的。
* 后续成员的偏移量则与前一个成员的偏移量和大小有关。编译器会根据对齐规则计算出每个成员的偏移量。
* 偏移量为0的意思就是这个成员在结构体的最开始位置,没有间隔。
举个例子:
 ```
struct A {
char a; // 偏移量为0
int b; // 偏移量为4(按4字节对齐)
};
```
这里a成员的偏移量就是0,因为它在结构体最开始的位置。而b成员相对于结构体起始地址有4字节的间隔,所以它的偏移量就是4。
总之,偏移量反映了结构体每个成员在内存布局中的确切位置。偏移量为0表示没有间隔,在最前面。
**offsetof** 是一个宏,定义在 **\** 头文件中,用于计算结构体中成员的偏移量(offset)。
在C语言中,结构体中的各个成员在内存中是按照声明的顺序依次排列的,每个成员在内存中占据一定的字节。**offsetof** 可以帮助我们确定结构体中特定成员相对于结构体起始地址的偏移量,以字节为单位。
**offsetof** 宏的使用方式如下:
```
offsetof(type, member)
```
其中:
* **type** 是结构体的类型
* **member** 是结构体中的成员名
**offsetof** 宏返回给定成员在给定结构体中的偏移量。
```
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 输出: │
│ Offset of member 'a' is 0 bytes │
│ Offset of member 'b' is 4 bytes │
│ Offset of member 'c' is 8 bytes │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
#include
#include
struct Example {
int a; //4,0
char b; //1,4
float c; //4,8
};
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ %zu 是C语言中用于格式化输出的格式说明符之一。 │
│ 它用于打印 size_t 类型的值,size_t 是无符号整数类型,通常用于表示内存大小或对象大小。 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
int main() {
size_t offset;
offset = offsetof(struct Example, a);
printf("Offset of member 'a' is %zu bytes\n", offset);
offset = offsetof(struct Example, b);
printf("Offset of member 'b' is %zu bytes\n", offset);
offset = offsetof(struct Example, c);
printf("Offset of member 'c' is %zu bytes\n", offset);
return 0;
}
```
上述程序图解如下:
```
struct A {
char a; // 偏移量为0
int b; // 偏移量为4(按4字节对齐)
};
```
这里a成员的偏移量就是0,因为它在结构体最开始的位置。而b成员相对于结构体起始地址有4字节的间隔,所以它的偏移量就是4。
总之,偏移量反映了结构体每个成员在内存布局中的确切位置。偏移量为0表示没有间隔,在最前面。
**offsetof** 是一个宏,定义在 **\** 头文件中,用于计算结构体中成员的偏移量(offset)。
在C语言中,结构体中的各个成员在内存中是按照声明的顺序依次排列的,每个成员在内存中占据一定的字节。**offsetof** 可以帮助我们确定结构体中特定成员相对于结构体起始地址的偏移量,以字节为单位。
**offsetof** 宏的使用方式如下:
```
offsetof(type, member)
```
其中:
* **type** 是结构体的类型
* **member** 是结构体中的成员名
**offsetof** 宏返回给定成员在给定结构体中的偏移量。
```
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 输出: │
│ Offset of member 'a' is 0 bytes │
│ Offset of member 'b' is 4 bytes │
│ Offset of member 'c' is 8 bytes │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
#include
#include
struct Example {
int a; //4,0
char b; //1,4
float c; //4,8
};
/*
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ %zu 是C语言中用于格式化输出的格式说明符之一。 │
│ 它用于打印 size_t 类型的值,size_t 是无符号整数类型,通常用于表示内存大小或对象大小。 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
*/
int main() {
size_t offset;
offset = offsetof(struct Example, a);
printf("Offset of member 'a' is %zu bytes\n", offset);
offset = offsetof(struct Example, b);
printf("Offset of member 'b' is %zu bytes\n", offset);
offset = offsetof(struct Example, c);
printf("Offset of member 'c' is %zu bytes\n", offset);
return 0;
}
```
上述程序图解如下:
 ### 6.1.6 对齐数说明
### 6.1.6 对齐数说明

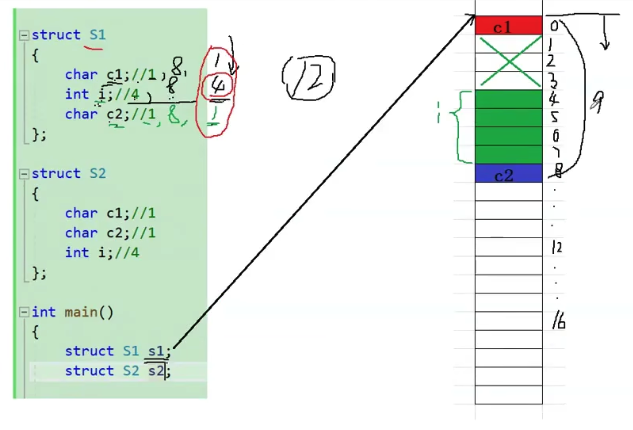 当前结构体 struct S1 ,char、int、char 的偏移量分别是:0、4、8,占有 9 个字节,浪费 3 个字节。
但是,按照对齐数要求,结构体变量的最大对齐数是4,相距 9 字节最近的 4 的整数倍为 12,则还需占位 3 个字节。
当前结构体 struct S1 ,char、int、char 的偏移量分别是:0、4、8,占有 9 个字节,浪费 3 个字节。
但是,按照对齐数要求,结构体变量的最大对齐数是4,相距 9 字节最近的 4 的整数倍为 12,则还需占位 3 个字节。
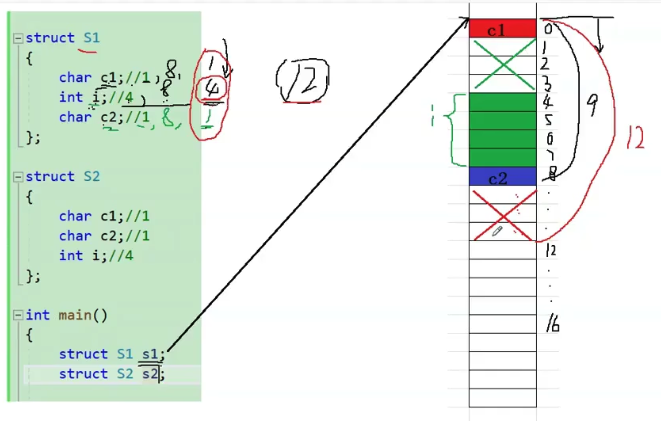 故此,一共浪费 6 个字节,结构体 struct S1 大小为 12 字节。
故此,一共浪费 6 个字节,结构体 struct S1 大小为 12 字节。